 View figure.
View figure.
This chapter is divided into the following sections:
It is helpful to create error logs when you are diagnosing a problem. See to "Step 11: Record and Control Log Files" for information on setting up error logs.
This section contains answers to questions frequently asked by LoadLeveler customers.
If you submitted your job and it is in the LoadLeveler queue but has not
run, issue llq -s first to help diagnose the problem. If you
need more help diagnosing the problem, refer to the following table:
| Why Your Job May Not Be Running: | Possible Soulution |
|---|---|
| Job requires specific machine, operating system, or other resource. |
Check the GUI to compare the job requirements to the machine details,
especially Arch, OpSys, and Class.
Ensure that the spelling and capitalization matches.
|
| Job requires specific job class |
|
| The maximum number of jobs are already running on all the eligible machines | Wait until one of the machines finishes a job before scheduling your job. |
| The start expression evaluates to false. | Examine the configuration files (both LoadL_config and
LoadL_config.local) to determine the START
control function expression used by LoadLeveler to start a job. As a
problem determination measure, set the START and SUSPEND values, as shown in
this example:
START: T SUSPEND: F |
| The priority of your job is lower than the priority of other jobs. | You cannot affect the system priority given to this job by the negotiator daemon but you can try to change your user priority to move this job ahead of other jobs you previously submitted using the llprio command or the GUI. |
| The information the central manager has about machines and jobs may not be current. | Wait a few minutes for the central manager to be updated and then the job may be dispatched. This time limit (a few minutes) depends upon the polling frequency and polls per update set in the LoadL_config file. The default polling frequency is five minutes. |
| You do not have the same user ID on all the machines in the cluster. | To run jobs on any machine in the cluster, you have to have the same user ID and the same uid number on every machine in the pool. If you do not have a userid on one machine, your jobs will not be scheduled to that machine. |
You can use the llq command to query the status of your job or the llstatus command to query the status of machines in the cluster. Refer to Chapter 9. "LoadLeveler Commands" for information on these commands.
If you submitted your parallel job and it is in the LoadLeveler queue but
has not run, issue llq -s first to help diagnose the
problem. If issuing this command does not help, refer to the previous
table and to the following table for more information:
| Why Your Job May Not Be Running | Possible Solution |
|---|---|
| The minimum number of processors requested by your job is not available. | Sufficient resources must be available. Specifying a smaller number of processors may help if your job can run with fewer resources. |
| The pool in your requirements statement specifies a pool which is invalid or not available. | The specified pool must be valid and available. |
| The adapter specified in the requirements statement or the network statement identifies an adapter which is invalid or not available. | The specified adapter must be valid and available. |
| PVM3 is not installed | PVM3 must be installed on any machine you wish to use for pvm. The PVM3 system itself is not supplied with LoadLeveler. |
| You are already running a PVM3 job on one of the LoadLeveler machines. | PVM3 restrictions prevent a user from running more than one pvm daemon per user per machine. If you want to run pvm3 jobs on LoadLeveler, you must not run any pvm3 jobs outside of LoadLeveler control on any machine being managed by LoadLeveler. |
| The parallel_path keyword in your job command file is incorrect. | Use parallel_path to inform LoadLeveler where binaries that run your pvm tasks are for the pvm_spawn() command. If this is incorrect, the job may not run. |
| The pvm_root keyword in the administration file is incorrect. | This keyword corresponds to the pvm ep keyword and is required to tell LoadLeveler where the pvm system is installed. |
| The file /tmp/pvmd.userid exists on some LoadLeveler machine but no PVM jobs are running. | If PVM3 exits unexpectedly, it will not properly clean up after itself. Although LoadLeveler attempts to clean up after pvm, some situations are ambiguous and you may have to remove this file yourself. Check all the systems specified as being capable of running PVM3, and remove this file if it exists. |
This section presents a list of common problems found in setting up parallel jobs:
If LoadLeveler is to manage PVM jobs on a machine for a user, that user should not attempt to run PVM jobs on that machine outside of LoadLeveler control. Because of PVM restrictions, only a single PVM daemon per user per machine is permitted. If a user tries to run PVM jobs without using LoadLeveler and LoadLeveler later attempts to start a job for that user on the same machine, LoadLeveler may not be able to start PVM for the job. This will cause the LoadLeveler job to be cancelled.
If a PVM job submitted through LoadLeveler is rejected, it is probably because PVM was not correctly terminated the last time it ran on the rejecting machine. LoadLeveler attempts to handle this by making sure that it cleans up PVM jobs when they complete, but remember that you may need to clean up after the job yourself. If a machine refuses to start a PVM job, check the following:
ps -ef | grep pvmd kill -TERM pid
Do not use either of the following variations to stop the daemon because this will prevent pvmd from cleaning up and jobs will still not start:
kill -9 pid kill -KILL pid
If a job you submitted from a submit-only machine does not run, verify that you have defined the following statements in the machine stanza of the administration file of the submit-only machine:
submit_only = true schedd_host = false central_manager = false
For other submit-only requirements, see the submit-only section.
If a job appears to stay in the Pending or Starting state, it is possible the job is continually being dispatched and rejected. Check the setting of the MAX_JOB_REJECT keyword. If it is set to the default, -1, the job will be rejected an unlimited number of times. Try resetting this keyword to some finite number. Also, check the setting of the ACTION_ON_MAX_REJECT keyword. These keywords are described in "Step 14: Specify Additional Configuration File Keywords".
Both the startd daemon and the schedd daemon maintain
persistent states of all jobs. Both daemons use a specific protocol to
ensure that the state of all jobs is consistent across LoadLeveler. In
the event of a failure, the state can be recovered. Neither the schedd
nor the startd daemon discard the job state information until it is passed
onto and accepted by another daemon in the process.
| If | Then |
|---|---|
| The network goes down but the machines are still running |
If the network goes down but the machines are still running, when
LoadLeveler is restarted, it looks for all jobs that were marked running when
it went down. On the machine where the job is running, the startd
daemon searches for the job and if it can verify that the job is still
running, it continues to manage the job through completion. On the
machine where schedd is running, schedd queues a transaction to the startd to
re-establish the state of the job. This transaction stays queued until
the state is established. Until that time, LoadLeveler assumes the
state is the same as when the system went down.
|
| The network partitions or goes down. | All transactions are left queued until the recipient has acknowledged them. Critical transactions such as those between the schedd and startd are recorded on disk. This ensures complete delivery of messages and prevents incorrect decisions based on incomplete state information. |
| The machine with startd goes down. | Because job state is maintained on disk in startd, when LoadLeveler is restarted it can forward correct status to the rest of LoadLeveler. In the case of total machine failure, this is usually "JOB VACATED", which causes the job to be restarted elsewhere. In the case that only LoadLeveler failed, it is often possible to "find" the job if it is still running and resume management of it. In this case LoadLeveler sends JOB RUNNING to the schedd and central manager, thereby permitting the job to run to completion. |
| The central manager machine goes down. | All machines in the cluster send current status to the central manager on
a regular basis. When the central manager restarts, it queries each
machine that checks in, requesting the entire queue from each machine.
Over the period of a few minutes the central manager restores itself to the
state it was in before the failure. Each schedd is responsible for
maintaining the correct state of each job as it progressed while the central
manager is down. Therefore, it is guaranteed that the central manager
will correctly rebuild itself.
All jobs started when the central manager was down will continue to run and complete normally with no loss of information. Users may continue to submit jobs. These new jobs will be forwarded correctly when the central manager is restarted. |
| The schedd machine goes down | When schedd starts up again, it reads the queue of jobs and for every job
which was in some sort of active state (i.e. PENDING, STARTING,
RUNNING), it queries the machine where it is marked active.
The running machine is required to return current status of the job. If the job completed while schedd was down, JOB COMPLETE is returned with exit status and accounting information. If the job is running, JOB RUNNING is returned. If the job was vacated, JOB VACATED is returned. Because these messages are left queued until delivery is confirmed, no job will be lost or incorrectly dispatched due to schedd failure. During the time the schedd is down, the central manager will not be able to start new jobs that were submitted to that schedd |
| The llsubmit machine goes down | schedd gets its own copy of the executable so it does not matter if the llsubmit machine goes down. |
If a machine fails while a job is running on the machine, the central manager does not change the status of any job on the machine. When the machine comes back up the central manager will be updated.
In one of your machine stanzas specified in the administration file, you specified a machine to serve as the central manager. It is possible for some problem to cause this central manager to become unusable such as network communication or software or hardware failures. In such cases, the other machines in the LoadLeveler cluster believe that the central manager machine is no longer operating. If you assigned one or more alternate central managers in the machine stanza, a new central manager will take control. The alternate central manager is chosen based upon the order in which its respective machine stanza appears in the administration file.
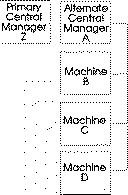
Once an alternate central manager takes control, it starts up its negotiator daemon and notifies all of the other machines in the LoadLeveler cluster that a new central manager has been selected. The following diagram illustrates how a machine can become the alternate central manager:
Figure 36. When the Primary Central Manager is Unavailable
| View figure. |
The diagram illustrates that Machine Z is the primary central manager but Machine A took control of the LoadLeveler cluster by becoming the alternate central manager. Machine A remains in control as the alternate central manager until either:
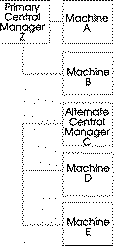
The following diagram illustrates how multiple central managers can function within the same LoadLeveler pool:
Figure 37. Multiple Central Managers
 View figure. View figure. |
In this diagram, the primary central manager is serving Machines A and B. Due to some network failure, Machines C, D, and E have lost contact with the primary central manager machine and, therefore, Machine C which is authorized to serve as an alternate central manager, assumes that role. Machine C remains as the alternate central manager until either:
While LoadLeveler can handle this situation of two concurrent central managers without any loss of integrity, some installations may find administering it somewhat confusing. To avoid any confusion, you should specify all primary and alternate central managers on the same LAN segment.
For information on selecting alternate central managers, refer to "Step 1: Specify Machine Stanzas"
The master daemon starts the startd daemon and the startd daemon starts the starter process. The starter process runs the job. The job needs to be run by the userid of the submitter. You either have to have a separate master daemon running for every ID on the system or the master daemon has to be able to su to every userid and the only user ID that can su any other userid is root.
When you submit a batch job to LoadLeveler, the operating system will execute your .profile script before executing the batch job if your login shell is the Korn shell. On the other hand, if your login shell is the Bourne shell, on most operating systems (including AIX), the .profile script is not executed. Similarly, if your login shell is the C shell then AIX will execute your .login script before executing your LoadLeveler batch job but some other variants of UNIX may not invoke this script.
The reason for this discrepancy is due to the interactions of the shells and the operating system. To understand the nature of the problem, examine the following C program that attempts to open a login Korn shell and execute the "ls" command:
#include <stdio.h>
main()
{
execl("/bin/ksh","-","-c","ls",NULL);
}
UNIX documentations in general (SunOS, HP-UX, AIX, IRIX) give the impression that if the second argument is "-" then you get a login shell regardless of whether the first argument is /bin/ksh or /bin/csh or /bin/sh. In practice, this is not the case. Whether you get a login shell or not is implementation dependent and varies depending upon the UNIX version you are using. On AIX you get a login shell for /bin/ksh and /bin/csh but not the Bourne shell.
If your login shell is the Bourne shell and you would like the operating system to execute your .profile script before starting your batch job, add the following statement to your job command file:
# @ shell = /bin/ksh
LoadLeveler will open a login Korn shell to start your batch job which may be a shell script of any type (Bourne shell, C shell, or Korn shell) or just a simple executable.
This section contains tips on running LoadLeveler, including some productivity aids.
By reading the notification mail you receive after submitting a job, you can determine the time the job was submitted, started, and stopped. Suppose you submit a job and receive the following mail when the job finishes:
Submitted at: Sun Apr 30 11:40:41 1996 Started at: Sun Apr 30 11:45:00 1996 Exited at: Sun Apr 30 12:49:10 1996 Real Time: 0 01:08:29 Job Step User Time: 0 00:30:15 Job Step System Time: 0 00:12:55 Total Job Step Time: 0 00:43:10 Starter User Time: 0 00:00:00 Starter System Time: 0 00:00:00 Total Starter Time: 0 00:00:00
This mail tells you the following:
You can also get the starting time by issing llsummary -l -x and then issuing awk `/Date|Event/` against the resulting file. For this to work, you must have ACCT = A_ON A_DETAIL set in the LoadL_config file.
Using a machine's local configuration file, you can set up the machine to run jobs at a certain time of day (sometimes called an execution window). The following coding in the local configuration file runs jobs between 5:00 PM and 8:00AM daily, and suspends jobs the rest of the day:
START: (tm_day >= 1700) || (tm_day <= 0800) SUSPEND: (tm_day > 0800) && (tm_day < 1700) CONTINUE: (tm_day >= 1700) || (tm_day <= 0800)
Three keywords determine the mix of idle and running jobs for a user. By a running job, we mean a job that is in one of the following states: Running, Pending, or Starting. These keywords, which are described in detail in "Step 2: Specify User Stanzas", are:
For a user's job to be allowed into the job queue, the total of other jobs (in the Idle, Pending, Starting and Running states) for that user must be less than the maxqueued value for that user. Also, the total idle jobs (those in the Idle, Pending, and Starting states) must be less than the maxidle value for the user. If either of these constraints are at the maximum, the job is placed in the Not Queued state until one of the other jobs changes state. If the user is at the maxqueued limit, a job must complete, be cancelled, or be held before the new job can enter the queue. If the user is at the maxidle limit, a job must start running, be cancelled, or be held before the new job can enter the queue.
Once a job is in the queue, the job is not taken out of queue unless the user places a hold on the job, the job completes, or the job is cancelled. (An exception to this, when you are running the default LoadLeveler scheduler, is parallel jobs which do not accumulate sufficient machines in a given time period. These jobs are moved to the Deferred state, meaning they must vie for the queue when their Deferred period expires.)
Once a job is in the queue, the job will run unless the maxjobs limit for the user is at a maximum.
Note the following restrictions for using these keywords:
You can use dependencies in your job command file to send the output from many job steps to the same output file. For example:
# @ step_name = step1 # @ executable = ssba.job # @ output = ssba.tmp # @ ... # @ queue # # @ step_name = append1 # @ dependency = (step1 != CC_REMOVED) # @ executable = append.ksh # @ output = /dev/null # @ queue # @ # @ step_name = step2 # @ dependency = (append1 == 0) # @ executable = ssba.job # @ output = ssba.tmp # @ ... # @ queue # @ # @ step_name = append2 # @ dependency = (step2 != CC_REMOVED) # @ executable = append.ksh # @ output = /dev/null # @ queue # # ...
Then, the file append.ksh could contain the line cat ssba.tmp >> ssba.log. All your output will reside in ssba.log. (Your dependecies can look for different return values, depending on what you need to accomplish.)
You can achieve the same result from within ssba.job by appending your output to an output file rather than writing it to stdout. Then your output statement for each step would be /dev/null and you wouldn't need the append steps.
You can define a machine to have multiple job classes which are active at different times. For example, suppose you want a machine to run jobs of Class A any time, and you want the same machine to run Class B jobs between 6 p.m. and 8 a.m.
You can combine the Class keyword with a user-defined macro (called Off_shift in this example).
For example:
Off_Shift = ((tm_hour >= 18) || (tm_hour < 8))
Then define your START statement:
START : (Class == "A") || ((Class == "B") && $(Off_Shift))
Make sure you have the parenthesis around the Off_Shift macro, since the logical OR has a lower precedence than the logical AND in the START statement.
Also, to take weekends into account, code the following statements. Remember that Saturday is day 6 and Sunday is day 0.
Off_Shift = ((tm_wday == 6) || (tm_wday == 0) || (tm_hour >=18) \ || (tm_hour < 8)) Prime_Shift = ((tm_wday != 6) && (tm_wday != 0) && (tm_hour >= 8) \ && (tm_hour < 18))
You can use the /usr/bin/rup command to report the load average on a machine. The rup machine_name command gives you a report that looks similar to the following:
localhost up 23 days, 10:25, load average: 1.72, 1.05, 1.17
You can use this command to report the load average of your local machine or of remote machines. Another command, /usr/bin/uptime, returns the load average information for only your local host.
The schedd daemon writes to the spool/history file only when a job is completed or removed. Therefore, you can delete the history file and restart schedd even when some jobs are scheduled to run on other hosts.
However, you should clean up the spool/job_queue.dir and spool/job_queue.pag files only when no jobs are being scheduled on the machine.
You should not delete these files if there are any jobs in the job queue that are being scheduled from this machine (for example, jobs with names such as thismachine.clusterno.jobno).
Should you require help from IBM in resolving a LoadLeveler problem, you can get assistance by calling IBM Support. Before you call, be sure you have the following information:
In addition, issue the following command:
llctl version
This command will provide you with code level information. Provide this information to the IBM representative.
The number for IBM support in the United States is 1-800-IBM-4YOU (426-4968).
The Facsimile number is 800-2IBM-FAX (2426-329).