 View figure.
View figure.
LoadLeveler provides several Application Programming Interfaces (API) that you can use. LoadLeveler's APIs are interfaces that allow application programs written by customers to interact with the LoadLeveler environment by using specific data or functions that are a part of LoadLeveler. These interfaces can be subroutines within a library or installation exits. This chapter also describes configuration file keywords required to enable these APIs.
This chapter discusses the following:
The header file llapi.h defines all of the API data structures and subroutines. This file is located in the include subdirectory of the LoadLeveler release directory. You must include this file when you call any API subroutine.
The library libllapi.a is a shared library containing all of the LoadLeveler API subroutines. This library is located in the lib subdirectory of the LoadLeveler release directory.
Attention: These APIs are not thread safe; They should not be linked to by a threaded application.
LoadLeveler provides two subroutines for accounting: one for account validation and one for extracting accounting data.
LoadLeveler provides the llacctval executable to perform account validation.
llacctval compares the account number a user specifies in a job command file with the account numbers defined for that user in the LoadLeveler administration file. If the account numbers match, llacctval returns a value of zero. Otherwise, it returns a non-zero value.
program user_name user_group user_acct# acct1 acct2 ...
llacctval is invoked from within the llsubmit command. If the return code is non-zero, llsubmit does not submit the job.
You can replace llacctval with your own accounting user exit (see below).
To enable account validation, you must specify the following keyword in the configuration file:
ACCT = A_VALIDATE
To use your own accounting exit, specify the following keyword in the configuration file:
ACCT_VALIDATION = pathname
where pathname is the name of your accounting exit.
If the validation succeeds, the exit status must be zero. If it does not succeed, the exit status must be a non-zero number.
LoadLeveler provides the GetHistory subroutine to generate accounting reports.
GetHistory processes local or global LoadLeveler history files.
LoadLeveler API library libllapi.a
#include "llapi.h" int GetHistory(char *filename, int (*func (LL_job *), int version);
GetHistory opens the history file you specify, reads one LL_job accounting record, and calls a user-supplied routine, passing to the routine the address of an LL_job structure. GetHistory processes all history records one at a time and then closes the file. Any user can call this subroutine.
The user-supplied function must include the following files:
#include sys/resource.h #include sys/types.h #include sys/time.h
The ll_event_usage structure is part of the LL_job structure and contains the following LoadLeveler defined data:
GetHistory returns a zero when successful.
GetHistory returns -1 to indicate that the version is not supported or that an error occurred opening the history file.
Makefiles and examples which use this API are located in the samples/llphist subdirectory of the release directory. The examples include the executable llpjob, which invokes GetHistory to print every record in the history file. In order to compile llpjob, the sample Makefile must update the RELEASE_DIR field to represent the current LoadLeveler release directory. The syntax for llpjob is:
llpjob history_file
Where history_file is a local or global history file.
This section describes ckpt, the subroutine used for user-initiated checkpointing of serial jobs. "Step 13: Enable Checkpointing" describes how to checkpoint your jobs in various ways including system-initiated and user-initiated. For information of checkpointing parallel jobs, see IBM Parallel Environment for AIX: Operation and Use, Volume 1 .
Specify the ckpt subroutine in a FORTRAN, C, or C++ program to activate user-initiated checkpointing. Whenever this subroutine is invoked, a checkpoint of the program is taken.
extern "C"{void ckpt();}
void ckpt();
call ckpt()
FORTRAN, C, and C++ programs can be compiled with the crxlf, crxlc, and crxlC programs, respectively. These programs are found in the bin subdirectory of the LoadLeveler release directory. See "Ensure all User's Jobs are Linked to Checkpointing Libraries" for information on using these compile programs.
This API allows you to submit jobs to LoadLeveler. The submit API consists of the llsubmit subroutine, the llfree_job_info subroutine, and the monitor program.
llsubmit is both the name of a LoadLeveler command used to submit jobs as well as the subroutine described here.
The llsubmit subroutine submits jobs to LoadLeveler for scheduling.
int llsubmit (char *job_cmd_file, char *monitor_program, char *monitor_arg, LL_job *job_info, int job_version);
LoadLeveler must be installed and configured correctly on the machine on which the submit application is run.
The uid and gid in effect when llsubmit is invoked is the uid and gid used when the job is run.
llfree_job_info frees space for the array and the job step information used by llsubmit.
void llfree_job_info(LL_job *job_info, int job_version);
You can create a monitor program that monitors jobs submitted using the llsubmit subroutine. The schedd daemon invokes this monitor program if the monitor_program argument to llsubmit is not null. The monitor program is invoked each time a job step changes state. This means that the monitor program will be informed when the job step is started, completed, vacated, removed, or rejected.
monitor_program job_id user_arg state exit_status
This API gives you access to LoadLeveler objects and allows you to retrieve specific data from the objects. You can use this API to query the negotiator daemon for information about its current set of jobs and machines. The Data Access API consists of the following subroutines: Ll_query, ll_set_request, ll_reset_request, ll_get_objs, ll_get_data, ll_next_obj, ll_free_objs, and ll_deallocate.
To use this API, you need to call the data access subroutines in the following order:
To see code that uses these subroutines, refer to "Examples of Using the Data Access API". For more information on LoadLeveler objects, see "Understanding the LoadLeveler Job Object Model".
The ll_query subroutine initializes the query object and defines the type of query you want to perform. The LL_element created and the corresponding data returned by this function is determined by the query_type you select.
LoadLeveler API library libllapi.a
#include "llapi.h" LL_element * ll_query(enum QueryType query_type);
query_type is the input field for this subroutine.
This subroutine is used in conjunction with other data access subroutines to query information about job and machine objects. You must call ll_query prior to using the other data access subroutines.
This subroutine returns a pointer to an LL_element object. The pointer is used by subsequent data access subroutine calls.
Subroutines: ll_get_data, ll_set_request, ll_reset_request, ll_get_objs, ll_free_objs, ll_next_obj, ll_deallocate.
The ll_set_request subroutine determines the data requested during a subsequent ll_get_objs call to query specific objects. You can filter your queries based on the query_type, object_filter, and data_filter you select.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_set_request(LL_element *query_element,QueryFlags query_flags, char **object_filter,DataFilter data_filter);
When query_type (in ll_query) is MACHINES, query_flags can be the following:
query_element, query_flags, object_filter, and data_filter are the input fields for this subroutine.
You can request a combination of object filters by calling ll_set_request more than once. When you do this, the query flags you specify are or-ed together. The following are valid combinations of object filters:
That is, to query jobs owned by certain users and on a specific machines, issue ll_set_request first with QUERY_USER and the appropriate user IDs, and then issue it again with QUERY_HOST and the appropriate host names.
For example, suppose you issue ll_set_request with a user ID list of anton and meg, and then issue it again with a host list of k10n10 and k10n11. The objects returned are all of the jobs on k10n10 and k10n11 which belong to anton or meg.
Note that if you use two consecutive calls with the same flag, the second call will replace the previous call.
Also, you should not use the QUERY_ALL flag in combination with any other flag, since QUERY_ALL will replace any existing requests.
This subroutine returns a zero to indicate success.
Subroutines: ll_get_data, ll_query, ll_reset_request, ll_get_objs, ll_free_objs, ll_next_obj, ll_deallocate.
The ll_reset_request subroutine resets the request data to NULL for the query_element you specify.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_reset_request(LL_element *query_element);
query_element is the input field for this subroutine.
This subroutine is used in conjunction with ll_set_request to change the data requested with the ll_get_objs subroutine.
This subroutine returns a zero to indicate success.
Subroutines: ll_get_data, ll_set_request, ll_query, ll_get_objs, ll_free_objs, ll_next_obj, ll_deallocate.
The ll_get_objs subroutine sends a query request to the daemon you specify along with the request data you specified in the ll_set_request subroutine. ll_get_objs receives a list of objects matching the request.
LoadLeveler API library libllapi.a
#include "llapi.h" LL_element * ll_get_objs(LL_element *query_element,LL_Daemon query_daemon, char *hostname,int *number_of_objs,int *error_code);
When query_type (in ll_query) is MACHINES, the query_flags (in ll_set_request) listed in the lefthand column are responded to by the daemons listed in the righthand column:
query_element, query_daemon, and hostname are the input fields for this subroutine. number_of_objs and error_code are output fields.
Each LoadLeveler daemon returns only the objects that it knows about.
This subroutine returns a pointer to the first object in the list. You must use the ll_next_obj subroutine to access the next object in the list.
This subroutine a NULL to indicate failure. The error_code parameter is set to one of the following:
Subroutines: ll_get_data, ll_set_request, ll_query, ll_get_objs, ll_free_objs, ll_next_obj, ll_deallocate.
The ll_get_data subroutine of the data access API allows you to access the LoadLeveler job model. The LoadLeveler job model consists of objects that have attributes and connections to other objects. An attribute is a characteristic of the object and generally has a primitive data type (such as integer, float, or character). The job name, submission time and job priority are examples of attributes.
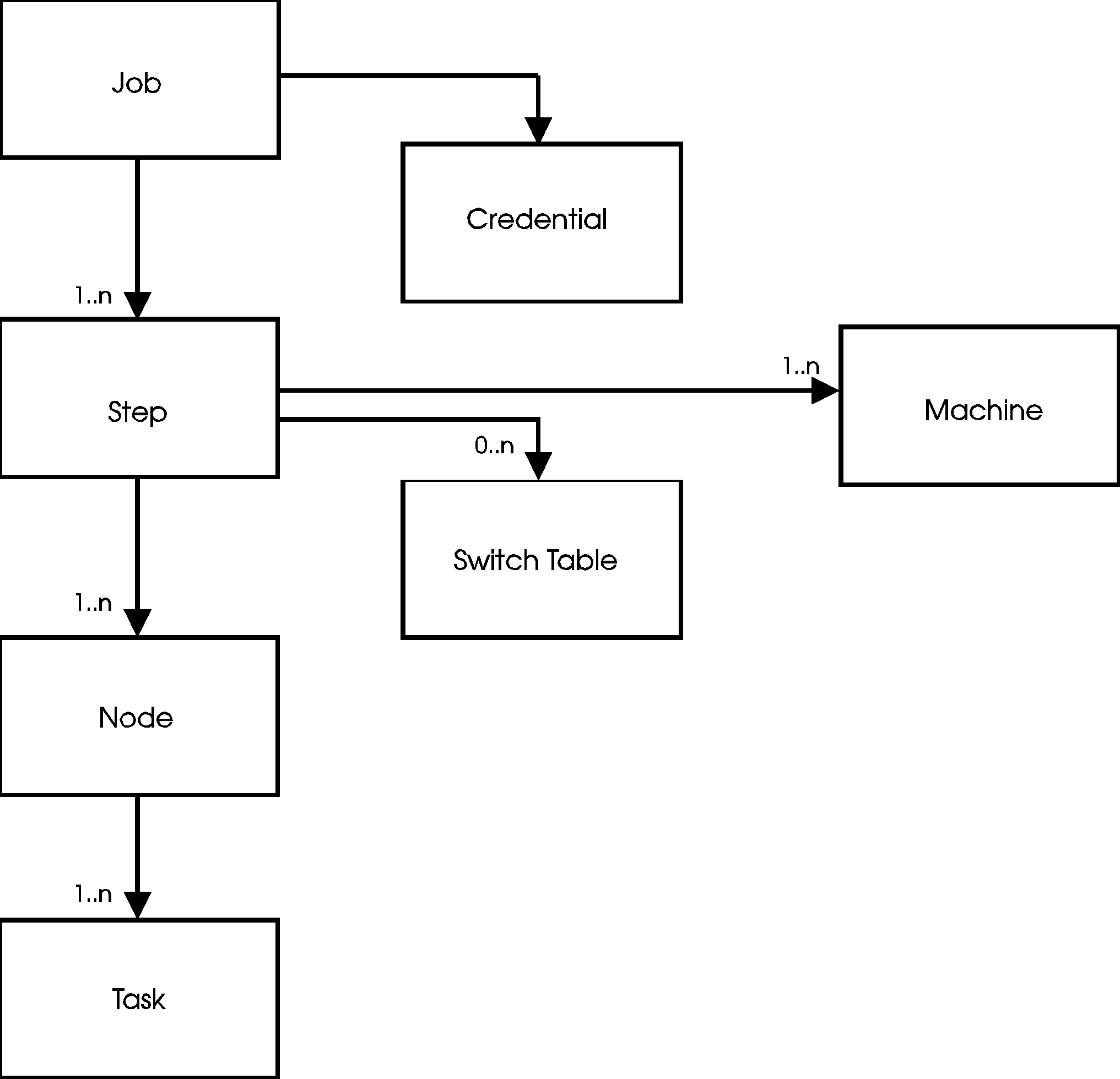
Objects are connected to one or more other objects via relationships. An object can be connected to other objects through more than one relationship, or through the same relationship. For example, A Job object is connected to a Credential object and to Step objects through two different relationships. A Job object can be connected to more than one Step object through the same relationship of "having a Step." When an object is connected through different relationships, different specifications are used to retrieve the appropriate object.
When an object is connected to more than one object through the same relationship, there are Count, GetFirst and GetNext specifications associated with the relationship. The Count operation returns the number of connections. You must use the GetFirst operation to initialize access to the first such connected object. You must use the GetNext operation to get the remaining objects in succession. You can not use GetNext after the last object has been retrieved.
You can use the ll_get_data subroutine to access both attributes and connected objects. See "ll_get_data Subroutine" for more information.
The root of the job model is the Job object, as shown in Figure 35. The job is queried for information about the number of steps it contains and the time it was submitted. The job is connected to a single Credential object and one or more Step objects. Elements for these objects can be obtained from the job.
You can query the Credential object to obtain the ID and group of the submitter of the job.
The Step object represents one executable unit of the job (all the tasks that are executed together). It contains information about the execution state of the step, messages generated during execution of the step, the number of nodes in the step, the number of unique machines the step is running on, the time the step was dispatched, the execution priority of the step, the unique identifier given to the step by LoadLeveler, the class of the step and the number of processes running for the step (task instances). The Step is connected to one or more Switch Table objects, one or more Machine objects and one or more Node objects. The list of Machines represents all of the hosts where one or more nodes of the step are running. If two or more nodes are running on the same host, the Machine object for the host occurs only once in the step's Machine list. The Step object is connected to one Switch Table object for each of the protocols (MPI and/or LAPI) used by the Step. Finally, the Step is connected to one or more Node objects.
Each Node object manages a set of executables that share common requirements and preferences. The Node can be queried for the number of tasks it manages, and is connected to one or more Task objects.
Figure 35. LoadLeveler Job Object Model
View figure.
The Task object represents one or more copies of the same executable. The Task object can be queried for the executable, the executable arguments, and the number of instances of the executable.
Table 11 describes the specifications and elements available when you use the ll_get_data subroutine. Each specification name describes the object you need to specify and the attribute returned. For example, the specification LL_JobGetFirstStep includes the object you need to specify (LL_Job) and the value returned (GetFirstStep).
This table is sorted alphabetically by object; within each object the
specifications are also sorted alphabetically.
Table 11. Specifications for ll_get_data Subroutine
| Specification | Object | Resulting Data Type | Description |
|---|---|---|---|
| LL_CredentialGid | Credential | int* | A pointer to an integer containing the UNIX gid of the user submitting the job. |
| LL_CredentialGroupName | Credential | char* | A pointer to a string containing the UNIX group name of the user submitting the job. |
| LL_CredentialUid | Credential | int* | A pointer to an integer containing the UNIX uid of the person submitting the job. |
| LL_CredentialUserName | Credential | char* | A pointer to a string containing the user ID of the user submitting the job. |
| LL_JobCredential | Job | LL_element* | A pointer to the element associated with the job the credential. |
| LL_JobGetFirstStep | Job | LL_element* | A pointer to the element associated with the first step of the job, to be used in subsequent ll_get_data calls. |
| LL_JobGetNextStep | Job | LL_element* | A pointer to the element associated with the next step. |
| LL_JobName | Job | char* | A pointer to a character string containing the job name. |
| LL_JobStepCount | Job | int* | A pointer to an integer indicating the number of steps connected to the job. |
| LL_JobStepType | Job | int* | A pointer to an integer indicating the type of job, which can be INTERACTIVE_JOB or BATCH_JOB. |
| LL_JobSubmitHost | Job | char* | A pointer to a character string containing the name of the host machine from which the job was submitted. |
| LL_JobSubmitTime | Job | time_t* | A pointer to the time_t structure indicating when the job was submitted. |
| LL_MachineAdapterList | Machine | char** | A pointer to an array containing the list of adapters associated with the machine. The array ends with a NULL string. |
| LL_MachineArchitecture | Machine | char* | A pointer to a string containing the machine architecture. |
| LL_MachineAvailableClassList | Machine | char** | A pointer to an array containing the currently available job classes defined on the machine. The array ends with a NULL string. |
| LL_MachineConfiguredClassList | Machine | char** | A pointer to an array containing the initiators on the machine. The array ends with a NULL string. |
| LL_MachineCPUs | Machine | int* | A pointer to an integer containing the number of CPUs on the machine. |
| LL_MachineDisk | Machine | int* | A pointer to an integer indicating the disk space in KBs on the machine. |
| LL_MachineFeatureList | Machine | char** | A pointer to an array containing the features defined on the machine. The array ends with a NULL string. |
| LL_MachineKbddIdle | Machine | int* | A pointer to an integer indicating the number of seconds since the kbdd daemon detected keyboard mouse activity. |
| LL_MachineLoadAverage | Machine | double* | A pointer to a double containing the load average on the machine. |
| LL_MachineMaxTasks | Machine | int* | A pointer to an integer indicating the maximum number of tasks this machine can run at one time. |
| LL_MachineMachineMode | Machine | char* | A pointer to a string containing the configured machine mode. |
| LL_MachineName | Machine | char* | A pointer to a string containing the machine name. |
| LL_MachineOperatingSystem | Machine | char* | A pointer to a string containing the operating system on the machine. |
| LL_MachinePoolList | Machine | int** | A pointer to an array indicating the pool numbers to which this machine belongs. The array ends with a NULL string. |
| LL_MachineRealMemory | Machine | int* | A pointer to an integer indicating the physical memory on the machine. |
| LL_MachineSpeed | Machine | double* | A pointer to a double containing the configured speed of the machine. |
| LL_MachineStartdRunningJobs | Machine | int* | A pointer to an integer containing the number of running jobs known by the startdd daemon. |
| LL_MachineStartdState | Machine | char* | A pointer to a string containing the state of the startdd daemon. |
| LL_MachineStepList | Machine | char** | A pointer to an array containing the steps running on the machine. The array ends with a NULL string. |
| LL_MachineTimeStamp | Machine | time_t* | A pointer to a time_t structure indicating the time the machine last reported to the negotiator. |
| LL_MachineVirtualMemory | Machine | int* | A pointer to an integer indicating the virtual memory in KBs on the machine. |
| LL_NodeGetFirstTask | Node | LL_element* | A pointer to the element associated with the first task for this node. |
| LL_NodeGetNextTask | Node | LL_element* | A pointer to the element associated with the next task for this node. |
| LL_NodeMinInstances | Node | int* | A pointer to an integer indicating the minimum number of machines requested. |
| LL_NodeMaxInstances | Node | int* | A pointer to an integer indicating the maximum number of machines requested. |
| LL_NodeRequirements | Node | char* | A pointer to a string containing the node requirements. |
| LL_NodeTaskCount | Node | int* | A pointer to an integer indicating the number of tasks running on the node. |
| LL_StepAccountNumber | Step | char* | A pointer to a string indicating the account number specified by the user submitting the job. |
| LL_StepAdapterUsage | Step | int* | A pointer to an integer indicating the adapter usage specified by the user, which can be SHARED or NOT_SHARED. |
| LL_StepComment | Step | char* | A pointer to a string indicating the comment specified by the user submitting the job. |
| LL_StepCompletionCode | Step | int* | A pointer to an integer indicating the completion code of the step. |
| LL_StepCompletionDate | Step | time_t* | A pointer to a time_t structure indicating the completion date of the step. |
| LL_StepCoreLimitHard | Step | int* | A pointer to an integer indicating the core hard limit set by the user in the core_limit keyword. |
| LL_StepCoreLimitSoft | Step | int* | A pointer to an integer indicating the core soft limit set by the user in the core_limit keyword. |
| LL_StepCpuLimitHard | Step | int* | A pointer to an integer indicating the CPU hard limit set by the user in the cpu_limit keyword. |
| LL_StepCpuLimitSoft | Step | int* | A pointer to an integer indicating the CPU soft limit set by the user in the cpu_limit keyword. |
| LL_StepCpuStepLimitHard | Step | int* | A pointer to an integer indicating the CPU step hard limit set by the user in the job_cpu_limit keyword. |
| LL_StepCpuStepLimitSoft | Step | int* | A pointer to an integer indicating the CPU step soft limit set by the user in the job_cpu_limit keyword. |
| LL_StepDataLimitHard | Step | int* | A pointer to an integer indicating the data hard limit set by the user in the data_limit keyword. |
| LL_StepDataLimitSoft | Step | int* | A pointer to an integer indicating the data soft limit set by the user in the data_limit keyword. |
| LL_StepDispatchTime | Step | time_t* | A pointer to a time_t structure indicating the time the negotiator dispatched the job. |
| LL_StepEnvironment | Step | char* | A pointer to a string containing the environment variables set by the user in the executable. |
| LL_StepErrorFile | Step | char* | A pointer to a string containing the standard error file name used by the executable. |
| LL_StepExecSize | Step | int* | A pointer to an integer indicating the executable size. |
| LL_StepFileLimitHard | Step | int* | A pointer to an integer indicating the file hard limit set by the user in the file_limit keyword. |
| LL_StepFileLimitSoft | Step | int* | A pointer to an integer indicating the file soft limit set by the user in the file_limit keyword. |
| LL_StepGetFirstMachine | Step | LL_element* | A pointer to the element associated with the first machine in the step. |
| LL_StepGetFirstNode | Step | LL_element* | A pointer to the element associated with the first node of the step. |
| LL_StepGetMasterTask | Step | LL_element* | A pointer to the element associated with the master task of the step. |
| LL_StepGetNextMachine | Step | LL_element* | A pointer to the element associated with the next machine of the step. |
| LL_StepGetNextNode | Step | LL_element* | A pointer to the element associated with the next node of the step. |
| LL_StepID | Step | char* | A pointer to a string containing the ID of the step. |
| LL_StepImageSize | Step | int* | A pointer to an integer indicating the image size of the executable. |
| LL_StepInputFile | Step | char* | A pointer to a string containing the standard input file name used by the executable. |
| LL_StepIwd | Step | char* | A pointer to a string containing the initial working directory name used by the executable. |
| LL_StepJobClass | Step | char* | A pointer to a string containing the class of the step. |
| LL_StepMachineCount | Step | int* | A pointer to an integer indicating the number of machines assigned to the step. |
| LL_StepName | Step | char* | A pointer to a string containing the name of the step. |
| LL_StepNodeCount | Step | int* | A pointer to an integer indicating the number of node objects associated with the step. |
| LL_StepNodeUsage | Step | int* | A pointer to an integer indicating the node usage specified by the user, which can be SHARED or NOT_SHARED. |
| LL_StepOutputFile | Step | char* | A pointer to a character string containing the standard output file name used by the executable. |
| LL_StepPriority | Step | int* | A pointer to an integer indicating the priority of the step. |
| LL_StepRssLimitHard | Step | int* | A pointer to an integer indicating the RSS hard limit set by the user in the rss_limit keyword. |
| LL_StepRssLimitSoft | Step | int* | A pointer to an integer indicating the RSS soft limit set by the user in the rss_limit keyword. |
| LL_StepShell | Step | char* | A pointer to a character string containing the shell name used by the executable. |
| LL_StepStackLimitHard | Step | int* | A pointer to an integer indicating the stack hard limit set by the user in the stack_limit keyword. |
| LL_StepStackLimitSoft | Step | int* | A pointer to an integer indicating the stack soft limit set by the user in the stack_limit keyword. |
| LL_StepStartCount | Step | int* | A pointer to an integer indicating the number of times the step has been started. |
| LL_StepStartDate | Step | time_t* | A pointer to a time_t structure indicating the value the user specified in the startdate keyword. |
| LL_StepState | Step | int* | A pointer to an integer indicating the state of the Step (Idle, Pending, Starting, etc.) The value returned is in the StepState enum. |
| LL_StepTaskInstanceCount | Step | int* | A pointer to an integer indicating the number of task instances in the step. |
| LL_StepWallClockLimitHard | Step | int* | A pointer to an integer indicating the wall clock hard limit set by the user in the wall_clock_limit keyword. |
| LL_StepWallClockLimitSoft | Step | int* | A pointer to an integer indicating the wall clock soft limit set by the user in the wall_clock_limit keyword. |
| LL_TaskExecutable | Task | char* | A pointer to a string containing the name of the executable. |
| LL_TaskExecutableArguments | Task | char* | A pointer to a string containing the arguments passed by the user in the executable. |
| LL_TaskIsMaster | Task | int* | A pointer to an integer indicating whether this is the master task. |
Before you use this subroutine, make sure you are familiar with "Understanding the LoadLeveler Job Object Model".
The ll_get_data subroutine returns data from a valid LL_element.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_get_data(LL_element *element, enum LLAPI_Specification specification, void* resulting_data_type);
object and specification are input fields, while resulting_data_type is an output field.
The ll_get_data subroutine of the data access API allows you to access LoadLeveler objects. The parameters of ll_get_data are a LoadLeveler object (LL_element), a specification that indicates what information about the object is being requested, and a pointer to the area where the information being requested should be stored.
If the specification indicates an attribute of the element that is passed in, the result pointer must be the address of a variable of the appropriate type. The type returned by each specification is found in Table 11. If the specification queries the connection to another object, the returned value is of type LL_element. You can use a subsequent ll_get_data call to query information about the new object.
The data type char* and any arrays of type int or char must be freed by the caller.
LL_element pointers cannot be freed by the caller
This subroutine returns a zero to indicate success.
Subroutines: ll_query, ll_set_request, ll_reset_request, ll_get_objs, lL_next_obj, ll_free_objs, ll_deallocate.
The ll_next_obj subroutine returns the next object in the query_element list you specify.
LoadLeveler API library libllapi.a
#include "llapi.h" LL_element * ll_next_obj(LL_element *query_element);
query_element is the input field for this subroutine.
Use this subroutine in conjunction with the ll_get_objs subroutine to "loop" through the list of objects queried.
This subroutine returns a pointer to the next object in the list.
Subroutines: ll_get_data, ll_set_request, ll_query, ll_get_objs, ll_free_objs, ll_deallocate.
The ll_free_objs subroutine frees all of the LL_element objects in the query_element list that were obtained by the ll_get_objs subroutine. You must free the query_element by using the ll_deallocate subroutine.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_free_objs(LL_element *query_element);
query_element is the input field for this subroutine.
This subroutine returns a zero to indicate success.
Subroutines: ll_get_data, ll_set_request, ll_query, ll_get_objs, ll_reset_request, ll_free_objs.
The ll_deallocate subroutine deallocates the query_element allocated by the ll_query subroutine.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_deallocate(LL_element *query_element);
query_element is the input field for this subroutine.
This subroutine returns a zero to indicate success.
Subroutines: ll_get_data, ll_set_request, ll_query, ll_get_objs, ll_reset_request, ll_next_obj, ll_free_objs.
Example 1: The following example obtains a list of current job objects from the negotiator and then prints the step ID and the name of the first allocated host.
#include "llapi.h"
main(int argc,char *argv[])
{
LL_element *queryObject=NULL, *job=NULL;
int rc, num, err, state;
LL_element *step=NULL, *machine = NULL;
char *id=NULL, *name=NULL;
/* Initialize the query for jobs */
queryObject = ll_query(JOBS);
/* I want to query all jobs */
rc = ll_set_request(queryObject,QUERY_ALL,NULL,NULL);
/* Request the objects from the Negotiator daemon */
job = ll_get_objs(queryObject,LL_CM,NULL,&num,&err);
/* Did we get a list of objects ? */
if (job == NULL) {
printf(" ll_get_objs returned a NULL object.\n");
printf(" err = %d\n",err);
}
else {
/* Loop through the list and process */
printf(" RESULT: number of jobs in list = %d\n",num);
while(job) {
rc = ll_get_data(job,LL_JobGetFirstStep, &step);
while (step) {
rc = ll_get_data(step,LL_StepID, &id);
rc = ll_get_data(step,LL_StepState,&state);
printf(" RESULT: step id: %s\n",id);
if (state == STATE_RUNNING) {
rc = ll_get_data(step,LL_StepGetFirstMachine, &machine);
rc = ll_get_data(machine,LL_MachineName, &name);
printf(" Running on 1st assigned host: %s.\n",name);
free(name);
}
else
printf(" Not Running.\n");
free(id);
rc=ll_get_data(job,LL_JobGetNextStep,&step);
}
job = ll_next_obj(queryObject);
}
}
/* free objects obtained from Negotiator */
rc = ll_free_objs(queryObject);
/* free query element */
rc = ll_deallocate(queryObject);
}
Example 2: The following example queries all jobs running under the class "small" from the host k10n04:
main(int argc,char *argv[])
{
LL_element *queryObject=NULL, *jobObject=NULL;
int rc, num, err;
LL_element *step=NULL, *cred=NULL, *machine=NULL;
char *class_list[1];
char *host_list[1];
char *id=NULL, *name=NULL;
/* Initialize the query for jobs */
queryObject = ll_query(JOBS);
/* Query all jobs on host k10n04 submitted to class "small" */
class_list[0] = (char *)malloc(10*sizeof(char *));
strcpy(class_list[0],"small");
rc = ll_set_request(queryObject,QUERY_CLASS,class_list,ALL_DATA);
host_list[0] = (char *)malloc(10*sizeof(char *));
strcpy(host_list[0],"k10n04");
rc = ll_set_request(queryObject,QUERY_HOST,host_list,ALL_DATA);
/* Request the objects from the Negotiator daemon */
jobObject = ll_get_objs(queryObject,LL_CM,NULL,&num,&err);
/* Did we get a list of objects ? */
if (jobObject == NULL) {
printf(" ll_get_objs returned a NULL object.\n");
printf(" err = %d\n",err);
}
else {
/* Loop through the list and process */
while(jobObject) {
printf(" RESULT: number of jobs in list = %d\n",num);
if(ll_get_data(jobObject,LL_JobCredential, &cred)){
printf("Couldn't get credential object.\n");
}
else {
if(!ll_get_data(cred,LL_CredentialUserName, &name)==0) {
printf("The owner of this job is %s\n",name);
free(name);
}
else {
printf("Couldn't get user name.\n");
}
}
if (ll_get_data(jobObject,LL_JobGetFirstStep, &step)==0) {
while (step) {
if(!ll_get_data(step,LL_StepID, &id)) {
printf(" RESULT: step id: %s\n",id);
}
ll_get_data(jobObject,LL_JobGetNextStep,&step);
}
}
else {
printf("No step associated with Job. Error !!\n");
exit(1);
}
jobObject = ll_next_obj(queryObject);
}
}
/* free objects obtained from Negotiator */
rc = ll_free_objs(queryObject);
/* free query element */
rc = ll_deallocate(queryObject);
}
Example 3: The following example queries information about the hosts k10n11 and k10n06:
#include "llapi.h"
main(int argc,char *argv[])
{
LL_element *queryObject=NULL, *machine=NULL;
int rc, num, err;
char **host_list;
char *state, *name;
/* Initialize the query for machines */
queryObject = ll_query(MACHINES);
/* I want to query two specific hostnames */
host_list = (char **)malloc(2*sizeof(char *));
host_list[0]=strdup("k10n11");
host_list[1]=strdup("k10n06");
rc = ll_set_request(queryObject,QUERY_HOST,host_list,NULL);
/* Request the objects from the Negotiator daemon */
machine = ll_get_objs(queryObject,LL_CM,NULL,&num,&err);
/* Did we get a list of objects ? */
if (machine == NULL) {
printf(" ll_get_objs returned a NULL object.\n");
printf(" err = %d\n",err);
}
else {
/* Loop through the list and process */
printf(" RESULT: number of machines in list = %d\n",num);
while(machine) {
rc = ll_get_data(machine,LL_MachineName,&name);
if (!rc) {
printf("machine name: %s\n",name);
free(name);
}
rc = ll_get_data(machine,LL_MachineStartdState,&state);
if (!rc) {
printf("startd state: %s\n",state);
free(state);
}
machine = ll_next_obj(queryObject);
}
}
/* free objects obtained from Negotiator */
rc = ll_free_objs(queryObject);
/* free query element */
rc = ll_deallocate(queryObject);
}
If you are using any of the parallel operating environments already supported by LoadLeveler, you do not have to use the parallel API. However, if you have another application environment that you want to use, you need to use the subroutines described here to interface with LoadLeveler.
The parallel job API consists of two subroutines. ll_get_hostlist acquires the list of LoadLeveler selected parallel nodes, and ll_start_host starts the parallel task under the LoadLeveler starter.
The following section describes how parallel job submission works. Understanding this will help you to better understand the parallel API.
This API does not give you access to any new LoadLeveler Version 2 Release 1.0 functions.
Program applications which use the parallel APIs to interface with LoadLeveler are supported under a job type called parallel. When a user submits a job specifying the keyword job_type equal to parallel, the LoadLeveler API job control flow is as follows:
The negotiator selects nodes based on the resources you request. Once the nodes have been obtained, the negotiator contacts the schedd to start the job. The schedd marks the job pending and contacts the affected startds to start their starter processes.
One machine becomes the Master Starter. The Master Starter is one of the selected parallel nodes. After all starters are started and have completed inititialization, the Master Starter starts the executable specified in the job command file. The executable referred to as the Parallel Master uses this API to start tasks on remote nodes. A LOADLBATCH environment variable is set to YES so that the Parallel Master can distinguish between callers.
The Parallel Master must:
When the Parallel Master starts, the job is marked Running. Once the Parallel Master and all tasks exit, the job is marked Complete.
The Parallel Master is expected to cleanup and exit when:
The SIGTERM is also sent to all parallel tasks.
The SIGUSR1 is also sent to all parallel tasks.
A SIGKILL is issued to any process which does not exit within two minutes of receiving a termination signal.
This subroutine obtains a list of machines from the Master Starter machine so that the Parallel Master can start the Parallel Slaves. The Parallel Master is the LoadLeveler executable specified in the job command file and the Parallel Slaves are the processes started by the Parallel Master through the ll_start_host API.
LoadLeveler API library libllapi.a
int ll_get_hostlist(struct JM_JOB_INFO* jobinfo);
jobinfo is a pointer to the JM_JOB_INFO structure defined in llapi.h. No fields are required to be filled in. ll_get_hostlist allocates storage for an array of JM_NODE_INFO structures and returns the pointer in the jm_min_node_info pointer. It is the caller's responsibility to free this storage.
struct JM_JOB_INFO {
int jm_request_type;
char jm_job_description[50];
enum JM_ADAPTER_TYPE jm_adapter_type;
int jm_css_authentication;
int jm_min_num_nodes;
struct JM_NODE_INFO *jm_min_node_info;
};
struct JM_NODE_INFO {
char jm_node_name [MAXHOSTNAMELEN];
char jm_node_address [50];
int jm_switch_node_number;
int jm_pool_id;
int jm_cpu_usage;
int jm_adapter_usage;
int jm_num_virtual_tasks;
int *jm_virtual_task_ids;
enum JM_RETURN_CODE jm_return_code;
};
The following data is filled in for the JM_JOB_INFO structure:
The following data is filled in for each JM_NODE_INFO structure:
The Parallel Master must:
This subroutine returns a zero to indicate success.
This subroutine starts a task on a selected machine.
LoadLeveler API library libllapi.a
int ll_start_host(char *host, char *start_cmd);
This function must be invoked for all the machines returned from the ll_get_hostlist subroutine once and only once by the Parallel Master. Acquiring the start_cmd is the responsibility of the Parallel Master. The user may pass this information through the arguments or environment keywords in the job command file.
The Parallel Master must:
This subroutine returns an integer greater than one to indicate the socket connected to the Parallel Slave's standard I/O (stdio)
A sample program called para_api.c is provided in the samples/llpara subdirectory of the release directory, usually /usr/lpp/LoadL/full.
In order to run this example, you need to do the following:
char *startCmd = "/home/user/para_api -s";
#!/bin/ksh # @ initialdir = /home/user # @ executable = para_api # @ output = para_api.$(cluster).$(process).out # @ error = para_api.$(cluster).$(process).err # @ job_type = parallel # @ min_processors = 2 # @ max_processors = 2 # @ queue |
The syntax to invoke the Parallel Master is:
para_api
The syntax to invoke the Parallel Slave is:
para_api -s
The Parallel Master does the following:
num_nodes=2 name=host1.kgn.ibm.com address=9.115.8.162 switch_number=-1 name=host2.kgn.ibm.com address=9.115.8.164 switch_number=-1 Connected to host1.kgn.ibm.com at sock 3 Received acko "8000" and acke "10000" from host 0 Connected to host2.kgn.ibm.com at sock 4 Received acko "8001" and acke "10001" from host 1 <Master Exiting>
The Parallel Slave does the following:
This API allows you to disable the default LoadLeveler scheduling algorithm and "plug in" an external scheduler. The job control API consists of two subroutines, ll_start_job and ll_terminate_job, and uses the SCHEDULER_API LoadLeveler configuration file keyword. This API is available to LoadLeveler administrators and to users.
To use the job control API, you must specify the following keyword in the global LoadLeveler configuration file:
SCHEDULER_API = YES
Specifying YES disables the default LoadLeveler scheduling algorithm. When you disable the default LoadLeveler scheduler, jobs do not start unless requested to do so by the job control API.
You can toggle between the default LoadLeveler scheduler and an external scheduler in the following ways. If you are running the default LoadLeveler scheduler, you can switch to an external scheduler by doing the following:
If you are running an external scheduler, you can re-enable the LoadLeveler scheduling algorithm by doing the following:
Note that the scheduling API automatically connects to an alternate central manager if the API cannot contact the primary central manager.
An example of an external scheduler you can use is the Extensible Argonne Scheduling sYstem (EASY), developed by Argonne National Laboratory and available as public domain code.
You should use this API in conjuction with the query API, which collects information regarding which machines are available and which jobs need to be scheduled. See "Query API" for more information.
This subroutine tells the LoadLeveler negotiator to start a job on the specified nodes.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_start_job(LL_start_job_info *ptr);
You must set SCHEDULER_API = YES in the global configuration file to use this subroutine.
Only jobs steps currently in the Idle state are started.
Only processes having the LoadLeveler administrator user ID can invoke this subroutine.
An external scheduler uses this subroutine in conjunction with the ll_get_nodes and ll_get_jobs subroutines of the query API. The query API returns information about which machines are avialable for scheduling and which jobs are currently in the job queue waiting to be scheduled.
This subroutines return a value of zero to indicate the start job request was accepted by the negotiator. However, a return code of zero does not necessarily imply the job started. You can use the llq command to verify the job started. Otherwise, this subroutine returns an integer value defined in the llapi.h file.
Makefiles and examples which use this subroutine are located in the samples/llsch subdirectory of the release directory. The examples include the executable sch_api, which invokes the query API and the job control API to start the second job in the list received from ll_get_jobs on two nodes. You should submit at least two jobs prior to running the sample. To compile sch_api, copy the sample to a writeable directory and update the RELEASE_DIR field to represent the current LoadLeveler release directory.
Subroutines: ll_get_jobs, ll_terminate_job, ll_get_nodes
This subroutine tells the negotiator to cancel the specified job step.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_terminate_job(LL_terminate_job_info *ptr);
You do not need to disable the default LoadLeveler scheduler in order to use this subroutine.
Only processes having the LoadLeveler administrator user ID can invoke this subroutine.
An external scheduler uses this subroutine in conjunction with the ll_get_job subroutine (of the job control API) and ll_start_jobs subroutine (of the query API).
This subroutine returns a value of zero when successful, to indicate the terminate job request was accepted by the negotiator. However, a return code of zero does not necessarily imply the negotiator cancelled the job. Use the llq command to verify the job was cancelled. Otherwise, this subroutine returns an integer value defined in the llapi.h file.
Makefiles and examples which use this subroutine are located in the samples/llsch subdirectory of the release directory. The examples include the executable sch_api, which invokes the query API and the job control API to terminate the first job reported by the ll_get_jobs subroutine. You should submit at least two jobs prior to running the sample. To compile sch_api, copy the sample to a writeable directory and update the RELEASE_DIR field to represent the current LoadLeveler release directory.
Subroutines: ll_get_jobs, ll_start_job, ll_get_nodes
It is important to know how LoadLeveler keywords and commands behave when you disable the default LoadLeveler scheduling algorithm. LoadLeveler scheduling keywords and commands fall into the following categories:
The following sections discuss some specific keywords and commands and how they behave when you disable the default LoadLeveler scheduling algorithm.
This API provides information about the jobs and machines in the LoadLeveler cluster. You can use this in conjuction with the job control API, since the job control API requires you to know which machines are available and which jobs need to be scheduled. See "Job Control API" for more information.
The query API consists of the following subroutines: ll_get_jobs, ll_free_jobs, ll_get_nodes, and ll_free_nodes.
This subroutine, available to any user, returns information about all jobs in the LoadLeveler job queue.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_get_jobs(LL_get_jobs_info *);
The LL_get_jobs_info structure contains an array of LL_job structures indicating each job in the LoadLeveler system.
Some job information, such as the start time of the job, is not available to this API. (It is recommended that you use the dispatch time, which is available, in place of the start time.) Also, some accounting information is not available to this API.
This subroutines returns a value of zero when successful. Otherwise, it returns an integer value defined in the llapi.h file.
Makefiles and examples which use this subroutine are located in the samples/llsch subdirectory of the release directory.
Subroutines: ll_free_jobs, ll_free_nodes, ll_get_nodes
This subroutine, available to any user, frees storage that was allocated by ll_get_jobs.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_free_jobs(LL_get_jobs_info *ptr);
This subroutine frees the storage pointed to by the LL_get_jobs_info pointer.
This subroutines returns a value of zero when successful. Otherwise, it returns an integer value defined in the llapi.h file.
Makefiles and examples which use this subroutine are located in the samples/llsch subdirectory of the release directory.
Subroutines: ll_get_jobs, ll_free_nodes, ll_get_nodes
This subroutine, available to any user, returns information about all of nodes known by the negotiator daemon.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_get_nodes(LL_get_nodes_info *ptr);
The LL_get_node_info structure contains an array of LL_job structures indicating each node in the LoadLeveler system.
This subroutines returns a value of zero when successful. Otherwise, it returns an integer value defined in the llapi.h file.
Makefiles and examples which use this subroutine are located in the samples/llsch subdirectory of the release directory.
Subroutines: ll_free_jobs, ll_free_nodes, ll_get_jobs
This subroutine, available to any user, frees storage that was allocated by ll_get_nodes.
LoadLeveler API library libllapi.a
#include "llapi.h" int ll_nodes_jobs(LL_get_nodes_info *ptr);
This subroutine frees the storage pointed to by the LL_get_nodes_info pointer.
This subroutines returns a value of zero when successful. Otherwise, it returns an integer value defined in the llapi.h file.
Makefiles and examples which use this subroutine are located in the samples/llsch subdirectory of the release directory.
Subroutines: ll_get_jobs, ll_free_nodes, ll_get_nodes
This section discusses separate user exits for the following:
You can write a pair of programs to override the default LoadLeveler DCE authentication method. To enable the programs, use the following keyword in your configuration file:
An example of a credentials object is a character string containing the DCE principle name and a password. program1 writes the following to standard output:
If program1 encounters errors, it writes error messages to standard error.
program2 receives the following as standard input:
program2 writes the following to standard output:
If program2 encounters errors, it writes error messages to standard error. The parent process, the LoadLeveler starter process, writes those messages to the starter log.
If you are using DCE on AIX 4.3, you need the proper DCE credentials for the existing authentication method in order to run a command or function that uses rshell (rsh). Otherwise, the rshell command may fail. You can use the lsauthent command to determine the authentication method. If lsauthent indicates that DCE authentication is in use, you must log in to DCE wth the dce_login command to obtain the proper credentials.
LoadLeveler commands that run rshell include llctl version and llctl start.
For examples of programs that enable DCE security credentials, see the /samples/lldce subdirectory in the release directory.
You can write a program, run by the scheduler, to refresh an AFS token when a job is started. To invoke the program, use the following keyword in your configuration file:
Before running the program, LoadLeveler sets up standard input and standard output as pipes between the program and LoadLeveler. LoadLeveler also sets up the following environment variables:
LoadLeveler writes the following current AFS credentials, in order, over the standard input pipe:
The ktc_principal structure is defined in the AFS header file afs_rxkad.h. The ktc_token structure is defined in the AFS header file afs_auth.h.
LoadLeveler expects to read these same structures in the same order from the standard output pipe, except these should be refreshed credentials produced by the user exit.
The user exit can modify the passed credentials (to extend their lifetime) and pass them back, or it can obtain new credentials. LoadLeveler takes whatever is returned and uses it to authenticate the user prior to starting the user's job.
You can write a program to filter a job script when the job is submitted. This program can, for example, modify defaults or perform site specific verification of parameters. To invoke the program, specify the following keyword in your configuration file:
The following environment variables are set when the program is invoked:
You can write a program to override the LoadLeveler default mail notification method. You can use this program to, for example, display your own messages to users when a job completes, or to automate tasks such as sending error messages to a network manager.
The syntax for the program is the same as it is for standard UNIX mail programs; the command is called with a list of users as arguments, and the mail message is taken from standard input. This syntax is as follows:
An administrator can write prolog and epilog user exits that can run before and after a LoadLeveler job runs, respectively.
Prolog and epilog programs fall into two categories: those that run as the LoadLeveler user ID, and those that run in a user's environment.
To specify prolog and epilog programs, specify the following keywords in the configuration file:
A user environment prolog or epilog runs with AFS and/or DCE authentification (if either is installed and enabled). For security reasons, you must code these programs on the machines where the job runs and on the machine that schedules the job. If you do not define a value for these keywords, the user enviroment prolog and epilog settings on the executing machine are ignored.
The user environment prolog and epilog can set environment variables for the job by sending information to standard output in the following format:
env id = value
Where:
For example, the user environment prolog below sets the environment variable STAGE_HOST for the job:
#!/bin/sh echo env STAGE_HOST=shd22
The prolog program is invoked by the starter process. Once the starter process invokes the prolog program, the program obtains information about the job from environment variables.
prolog_program
Where prolog_program is the name of the prolog program as defined in the JOB_PROLOG keyword.
No arguments are passed to the program but several environment variables are set. These environment variables are described in "Submitting a Job Command File".
The real and effective user ID of the prolog process is the LoadLeveler user ID. If the prolog program requires root authority, the administrator must write a secure C or perl program to perform the desired actions. You should not use shell scripts with set uid permissions, since these scripts may make your system susceptible to security problems.
If the prolog program is killed, the job does not begin and a message is written to the starter log.
#!/bin/ksh
#
# Set up environment
set -a
. /etc/environment
. ~/.profile
export PATH="$PATH:/loctools/lladmin/bin"
export LOG="/tmp/$LOADL_STEP_OWNER.$LOADL_JOB_ID.prolog"
#
# Do set up based upon job step class
#
case $LOADL_STEP_CLASS in
# A OSL job is about to run, make sure the osl filesystem is
# mounted. If status is negative then filesystem cannot be
# mounted and the job step should not run.
"OSL")
mount_osl_files >> $LOG
if [ status = 0 ]
then EXIT_CODE=1
else
EXIT_CODE=0
fi
;;
# A simulation job is about to run, simulation data has to
# be made available to the job. The status from copy script must
# be zero or job step cannot run.
"sim")
copy_sim_data >> $LOG
if [ status = 0 ]
then EXIT_CODE=0
else
EXIT_CODE=1
fi
;;
# All other job will require free space in /tmp, make sure
# enough space is available.
*)
check_tmp >> $LOG
EXIT_CODE=$?
;;
esac
# The job step will run only if EXIT_CODE == 0
exit $EXIT_CODE
#!/bin/csh
#
# Set up environment
source /u/loadl/.login
#
setenv PATH "${PATH}:/loctools/lladmin/bin"
setenv LOG "/tmp/${LOADL_STEP_OWNER}.${LOADL_JOB_ID}.prolog"
#
# Do set up based upon job step class
#
switch ($LOADL_STEP_CLASS)
# A OSL job is about to run, make sure the osl filesystem is
# mounted. If status is negative then filesystem cannot be
# mounted and the job step should not run.
case "OSL":
mount_osl_files >> $LOG
if ($status < 0 ) then
set EXIT_CODE = 1
else
set EXIT_CODE = 0
endif
breaksw
# A simulation job is about to run, simulation data has to
# be made available to the job. The status from copy script must
# be zero or job step cannot run.
case "sim":
copy_sim_data >> $LOG
if ($status == 0 ) then
set EXIT_CODE = 0
else
set EXIT_CODE = 1
endif
breaksw
# All other job will require free space in /tmp, make sure
# enough space is available.
default:
check_tmp >> $LOG
set EXIT_CODE = $status
breaksw
endsw
# The job step will run only if EXIT_CODE == 0
exit $EXIT_CODE
The installation defined epilog program is invoked after a job step has completed. The purpose of the epilog program is to perform any required clean up such as unmounting file systems, removing files, and copying results. The exit status of both the prolog program and the job step is set in environment variables.
epilog_program
Where epilog_program is the name of the epilog program as defined in the JOB_EPILOG keyword.
No arguments are passed to the program but several environment variables are set. These environment variables are described in "Submitting a Job Command File".
To interpret the exit status of the prolog program and the job step, convert the string to an integer and use the structures found in the sys/wait.h file.
#!/bin/ksh
#
# Set up environment
set -a
. /etc/environment
. ~/.profile
export PATH="$PATH:/loctools/lladmin/bin"
export LOG="/tmp/$LOADL_STEP_OWNER.$LOADL_JOB_ID.epilog"
#
if [ [ -z $LOADL_PROLOG_EXIT_CODE ] ]
then
echo "Prolog did not run" >> $LOG
else
echo "Prolog exit code = $LOADL_PROLOG_EXIT_CODE" >> $LOG
fi
#
if [ [ -z $LOADL_USER_PROLOG_EXIT_CODE ] ]
then
echo "User environment prolog did not run" >> $LOG
else
echo "User environment exit code = $LOADL_USER_PROLOG_EXIT_CODE" >> $LOG
fi
#
if [ [ -z $LOADL_JOB_STEP_EXIT_CODE ] ]
then
echo "Job step did not run" >> $LOG
else
echo "Job step exit code = $LOADL_JOB_STEP_EXIT_CODE" >> $LOG
fi
#
#
# Do clean up based upon job step class
#
case $LOADL_STEP_CLASS in
# A OSL job just ran, unmount the filesystem.
"OSL")
umount_osl_files >> $LOG
;;
# A simulation job just ran, remove input files.
# Copy results if simulation was successful (second argument
# contains exit status from job step).
"sim")
rm_sim_data >> $LOG
if [ $2 = 0 ]
then copy_sim_results >> $LOG
fi
;;
# Clean up /tmp
*)
clean_tmp >> $LOG
;;
esac
#!/bin/csh
#
# Set up environment
source /u/loadl/.login
#
setenv PATH "${PATH}:/loctools/lladmin/bin"
setenv LOG "/tmp/${LOADL_STEP_OWNER}.${LOADL_JOB_ID}.prolog"
#
if ( ${?LOADL_PROLOG_EXIT_CODE} ) then
echo "Prolog exit code = $LOADL_PROLOG_EXIT_CODE" >> $LOG
else
echo "Prolog did not run" >> $LOG
endif
#
if ( ${?LOADL_USER_PROLOG_EXIT_CODE} ) then
echo "User environment exit code = $LOADL_USER_PROLOG_EXIT_CODE" >> $LOG
else
echo "User environment prolog did not run" >> $LOG
endif
#
if ( ${?LOADL_JOB_STEP_EXIT_CODE} ) then
echo "Job step exit code = $LOADL_JOB_STEP_EXIT_CODE" >> $LOG
else
echo "Job step did not run" >> $LOG
endif
#
# Do clean up based upon job step class
#
switch ($LOADL_STEP_CLASS)
# A OSL job just ran, unmount the filesystem.
case "OSL":
umount_osl_files >> $LOG
breaksw
# A simulation job just ran, remove input files.
# Copy results if simulation was successful (second argument
# contains exit status from job step).
case "sim":
rm_sim_data >> $LOG
if ($argv{2} == 0 ) then
copy_sim_results >> $LOG
endif
breaksw
# Clean up /tmp
default:
clean_tmp >> $LOG
breaksw
endsw